
大模型微调(指令微调/有监督微调)
1.1简介
模型微调,称为指令微调(Instruction Tuning)或者有监督微调(Supervised Fine-tuning,SFT):使用成对的输入与预期的输出,训练模型学会以问答的形式解答问题。
-
经过微调之后,大模型展现较强的指令遵循能力,后可以通过零样本学习的方式解决多种下游任务。
-
指令微调还是扮催化剂的角色,激活模型内在的潜力,而非单纯灌输信息。
1.1.1预训练对比
指令微调/有监督微调,所需数据显著减少,从十几万到上百万条,均能有效激发模型的通用任务解决能力;甚至有些少量高质量的指令数据,(数千条数万条)也能实现很好的效果。
- 降低了对计算资源的依赖,也提升了微调的灵活性与效率。
1.2轻量化微调技术(Lightweight Fine-tuning)参数高效微调
由于大模型的参数量巨大,进行**全量参数微调**需要消耗非常多的算力,为了解决这一问题,提出:
**参数高效微调**(**P**arameter-efficient **F**ine-tuning)/轻量化微调(**L**ightweight **F**ine-tuning):通过训来拿极少的模型参数,也能保证微调后的模型表现可以与全量微调普美。
- 常用的轻量化微调技术:LoRA、Adapter和Prompt Tuning
1.3LoRA技术(不是LoRa
LoRA(Low-Rank Adaptation)一种降低语言模型微调参数数量的技术
翻译是”低秩适配“的意思
通过低秩矩阵分解,在原始矩阵的基础上增加一个旁路矩阵,然后只更新旁路矩阵的参数。
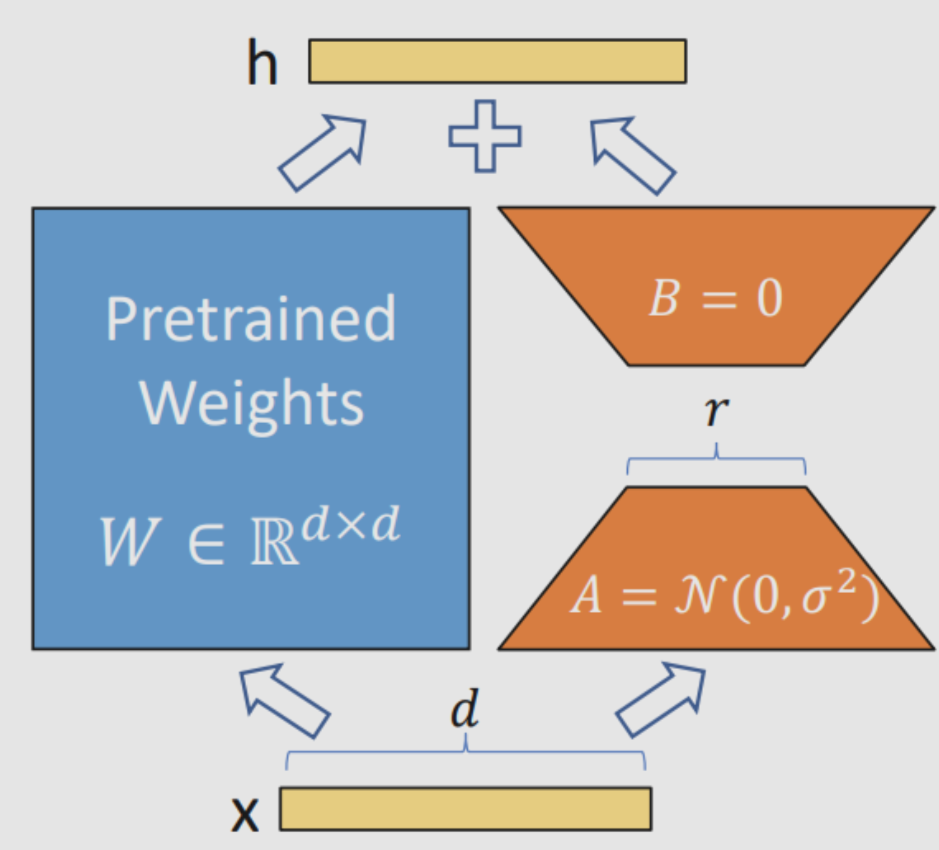
实例:
使用简历命名实体识别的数据集,进行微调,进而开发一个AI简历助手,后能批量地自动识别并提取简历中的关键信息(姓名、教育背景、工作经历等)提升效率。
具体来说,输入一个摘录自某简历的句子,模型需要识别出所有的命名实体。实体的类别包括:姓名(NAME)国籍(CONT)、种族(RACE)、职位(TITLE)、教育背景(EDU)、专业(PRO)、组织名(ORG)、地名(LOC)。原始的数据来自于BAAI/COIG-PC-Lite · Datasets at HF Mirror (hf-mirror.com)
torch、transformer、streamlit安装
下载模型
数据处理pandas进行数据读取,转为Dataset格式
[‘input’:[’#任务描述\n假设你是一个AI简历助手,能从简历中识别出所有的命名实体,并以json格式返回结果。\n\n#任务要求1n实体的类别包括:姓名、国籍、种族、职位、教育背景、专业、组织名、地名。1n返回的jso格式是一个字典,其中每个键 是实体的类别,值是一个列表,包含实体的文本。\n\n#样例小n输入:\n张三,男,中国籍,工程师1n输出:1n(“姓名”:[“张三”],“国籍”:[“中国”],“职位”:[“工程师”]}八n\n#当前简历\n高勇:男,中国国籍,无境外居留权,\n\n#任务重述\n请 参考样例,按照任务要求,识别出当前简历中所有的命名实体,并以jso格式返回结果。·],‘output’:[’{“姓名”:[“高勇”],“国籍”:[“中国国籍”]}’]}
加载tokenizer
定义数据处理函数
def process_func (example):
MAX_LENGTH = 384 #Llama分词器会将中文字切分为多个token因此需要放开一些最大长度,保证数据的完整性。
instruction = tokenizer (f "{example ['input']} < sep >")
Response = tokenizer (f "{example ['output']} < eod >")
input_ids = instruction ["input_ids"] + response ["input_ids"]
attention_mask = [1] * len (input_ids)
Labels = [-100] * len (instruction ["input_ids"]) + response ["input_ids"] #instruction 不计算loss
if len (input_ids) > MAX_LENGTH: # 做一个截断
input_ids = input_ids [: MAX_LENGTH]
attention_mask = attention_mask [: MAX_LENGTH]
Labels = labels [: MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"Labels": labels
}
需要使用tokenizer讲文本转为id,同时讲input和output凭借,组成input_ids和attention_mask
源大模型需要在input后面添加一个特殊的token在output后面添加一个特殊的token,同时为了防止数据超长进行了一个阶段处理。
然后使用map函数对整个数据集进行预处理。
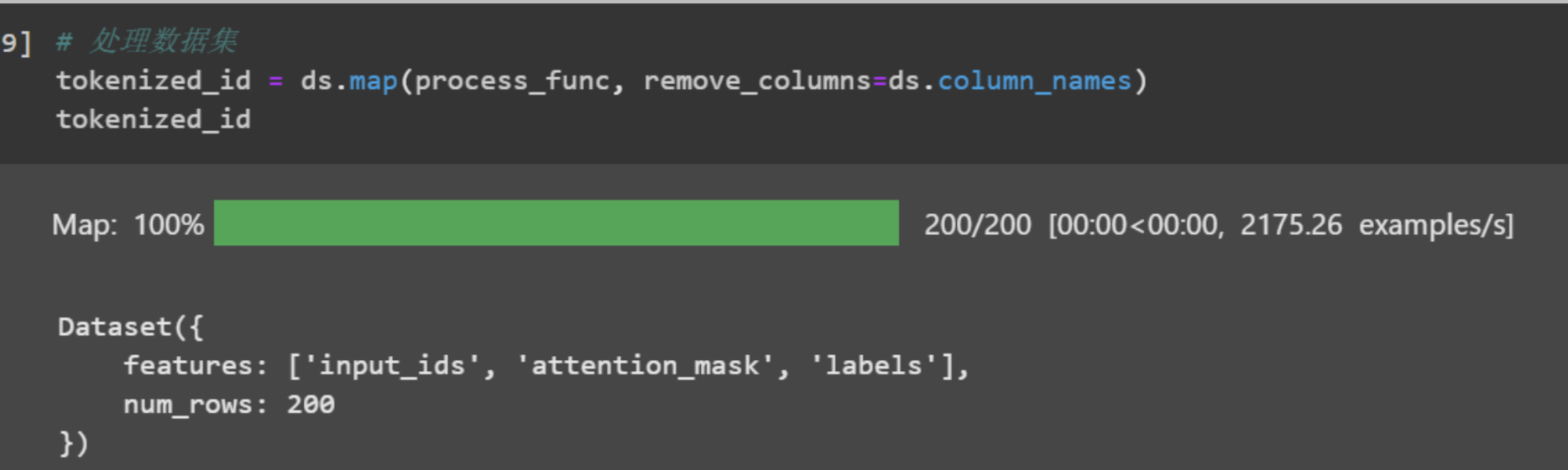
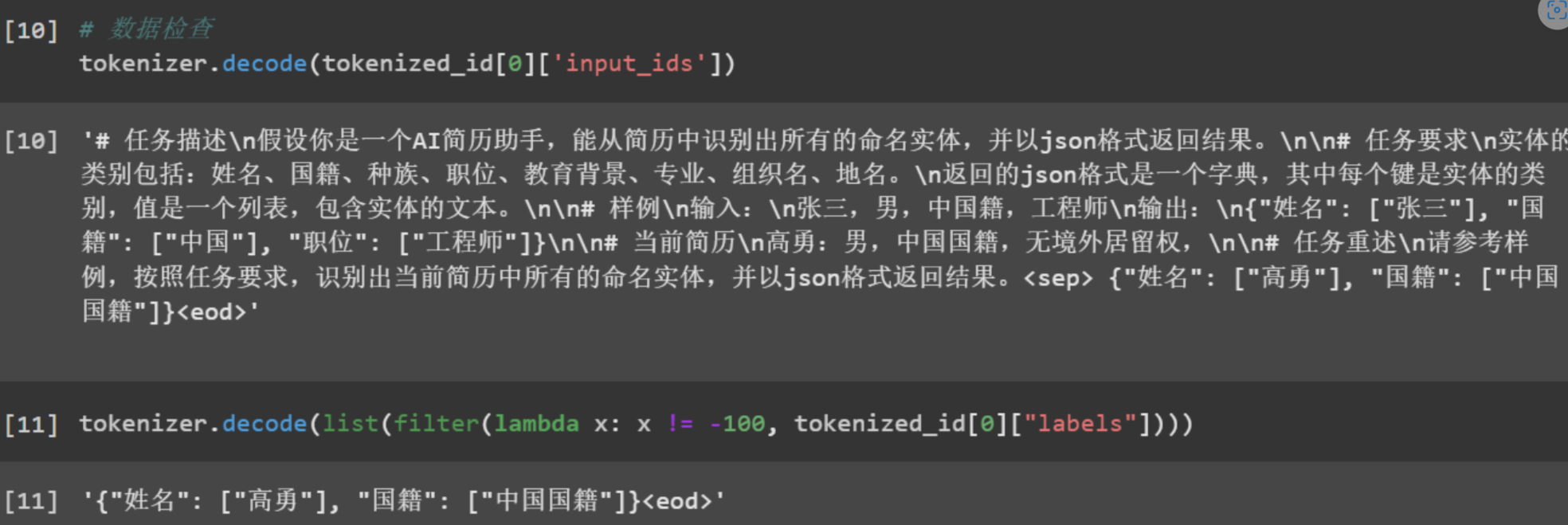
处理完毕后,使用tokenizer的decode函数,将id转回文本,进行最后的检查:
2.4模型训练
加载大模型参数,然后打印模型结构
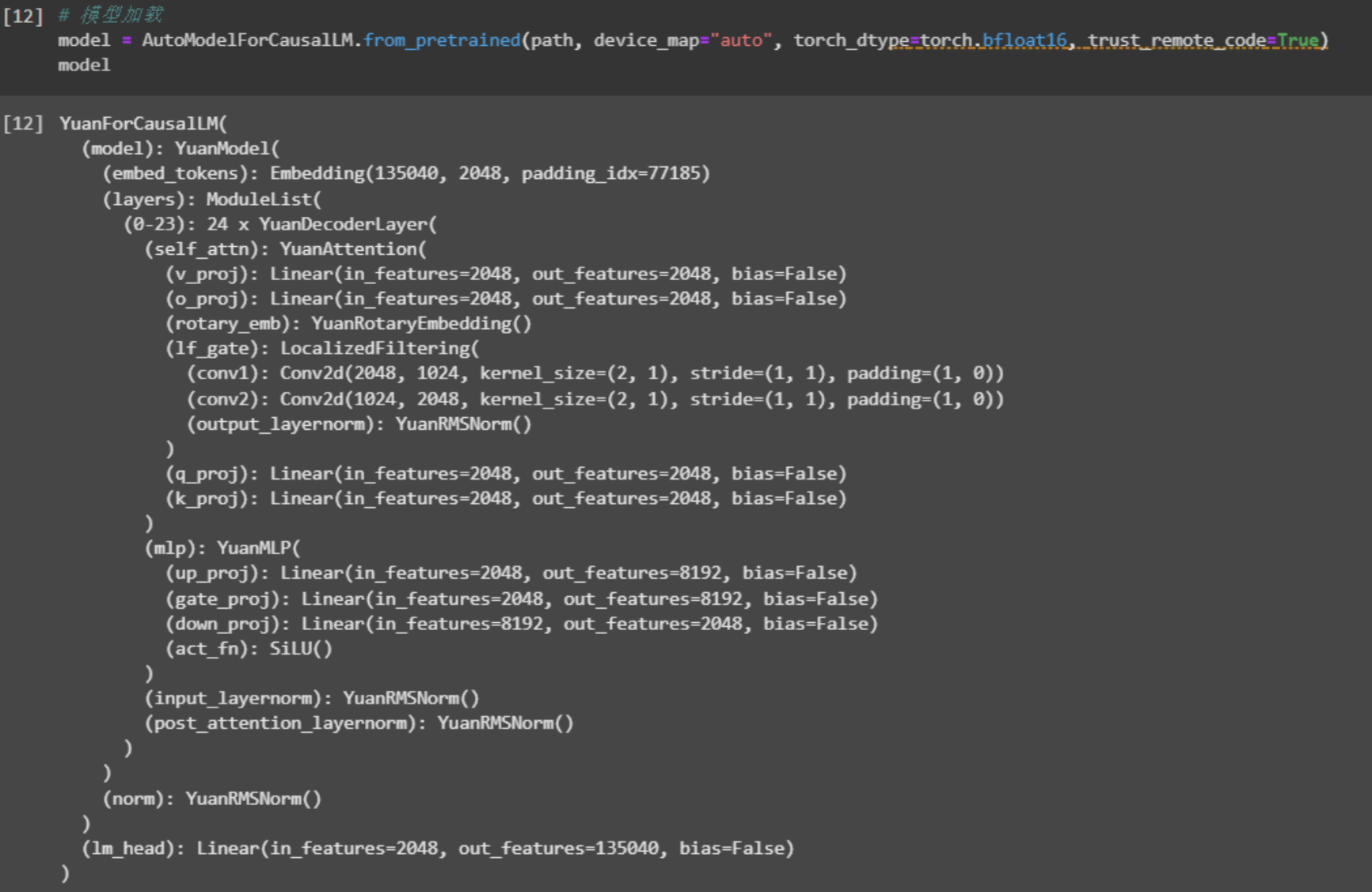
Yuan大模型中包含24层YuanDecoderLayer每层包含self_attn、mpl和layernorm。
为了进行模型使用训练,需要先执行,model.enable_input_require_grads()

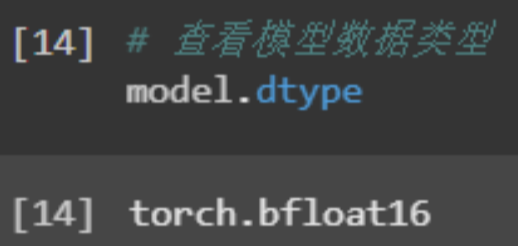
最后打印模型的数据类型,可以看到是torch.bfloat16
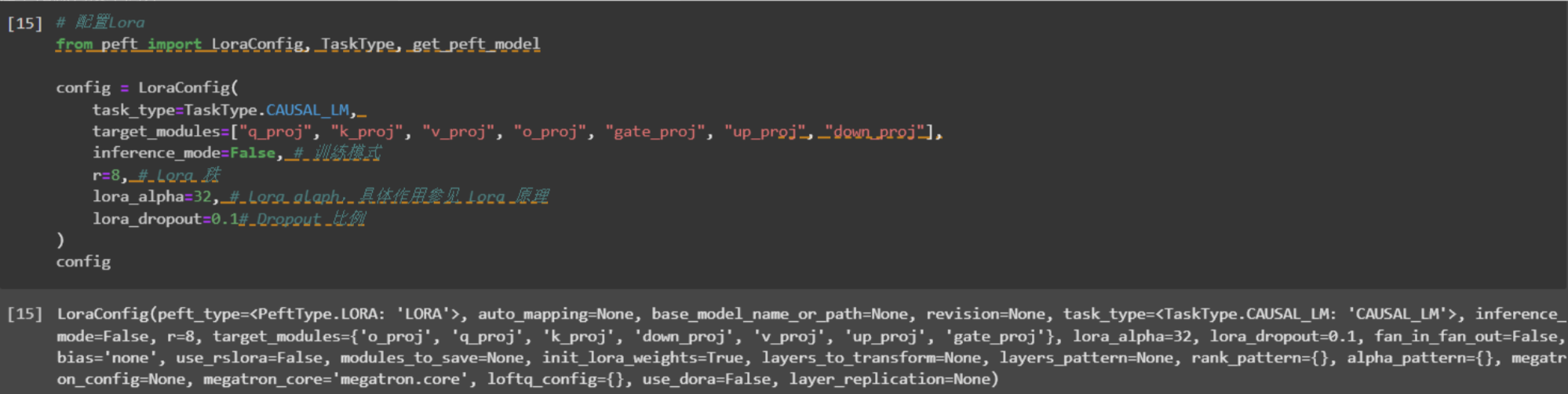
使用lora进行轻量化微调
配置LoraConfig
构建一个PeftModel
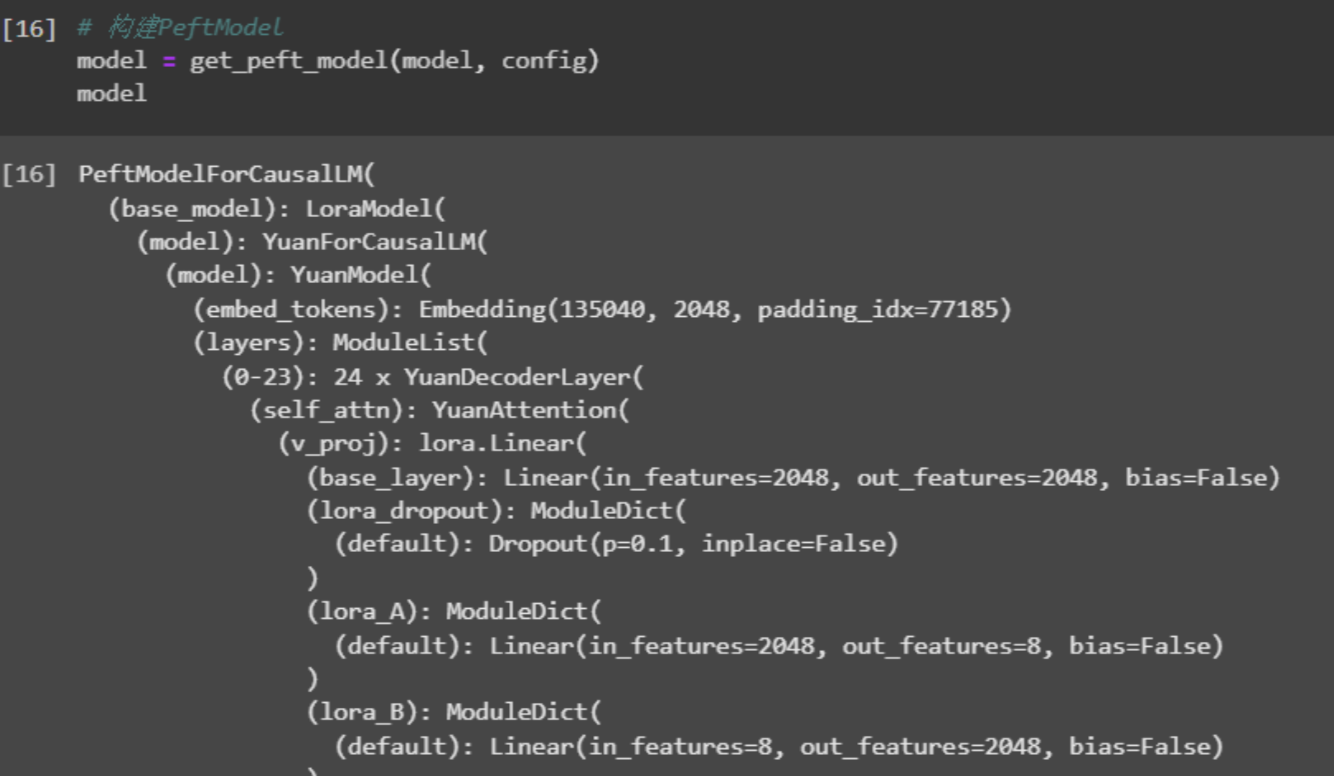
通过mdoel.print_trainable_parameters()可以看到需要训练的参数在所有参数中的占比

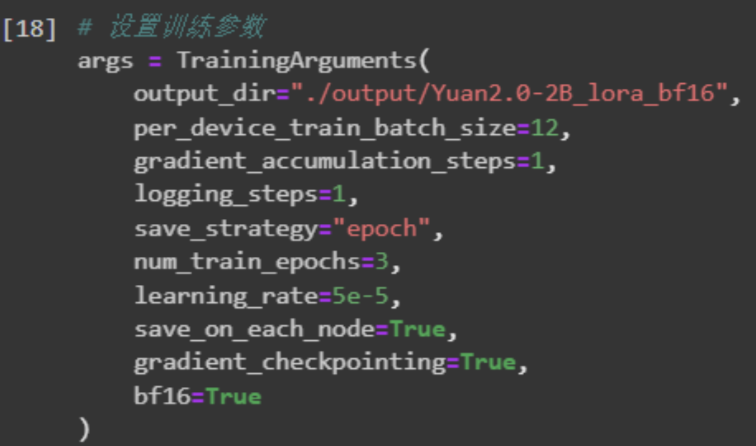
然后,设置训练参数TrainingArguments
同时初始化一个Trainer:

最后允许trainer.train()j执行模型训练。
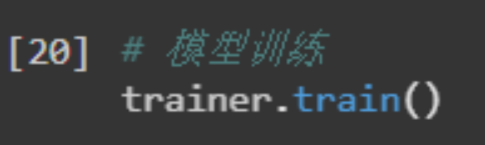
训练过程中会打印模型训的loss,我们可以通过loss降低的情况,检查模型是否收敛。
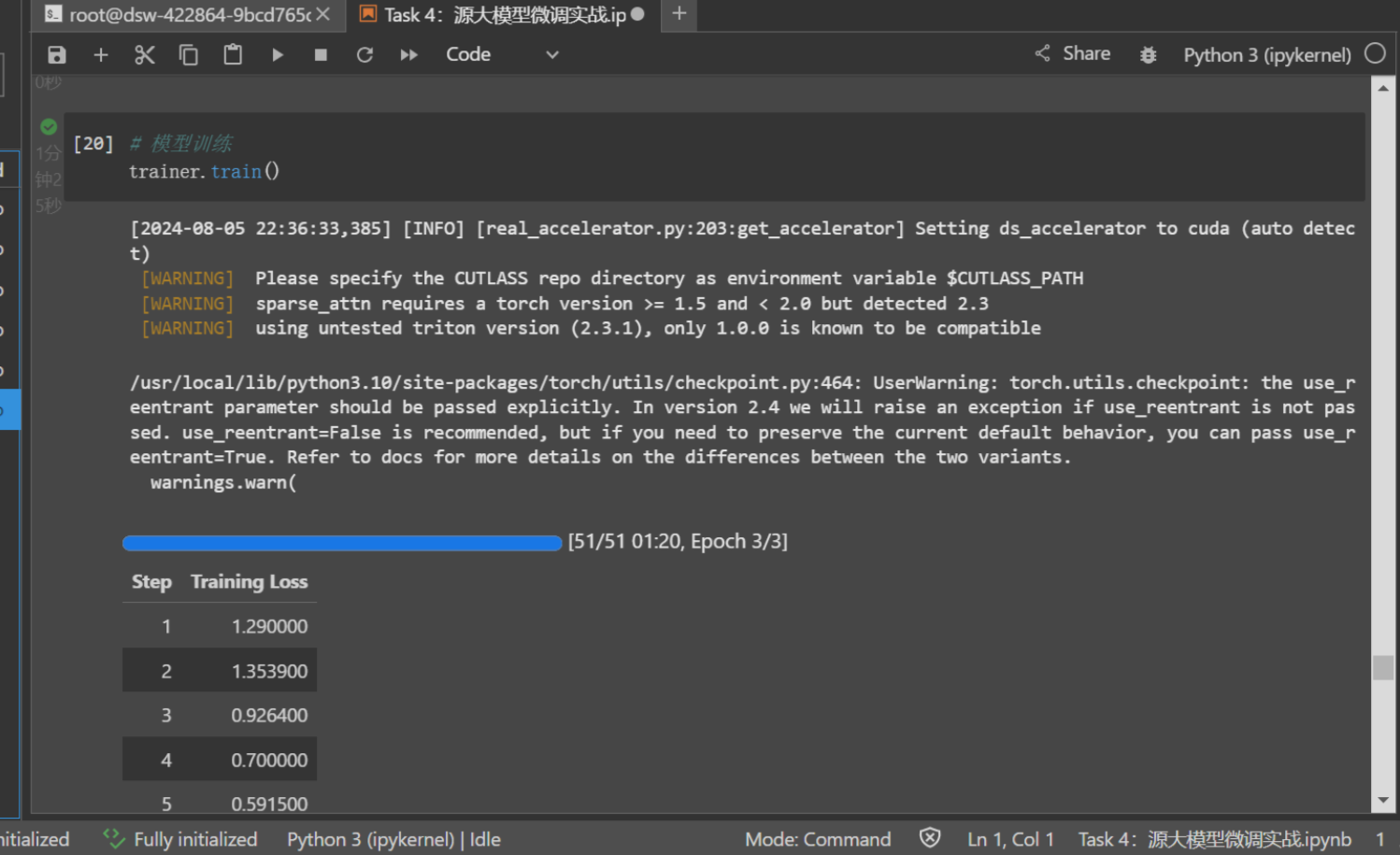
训练完成后,会打印训练相关的信息:

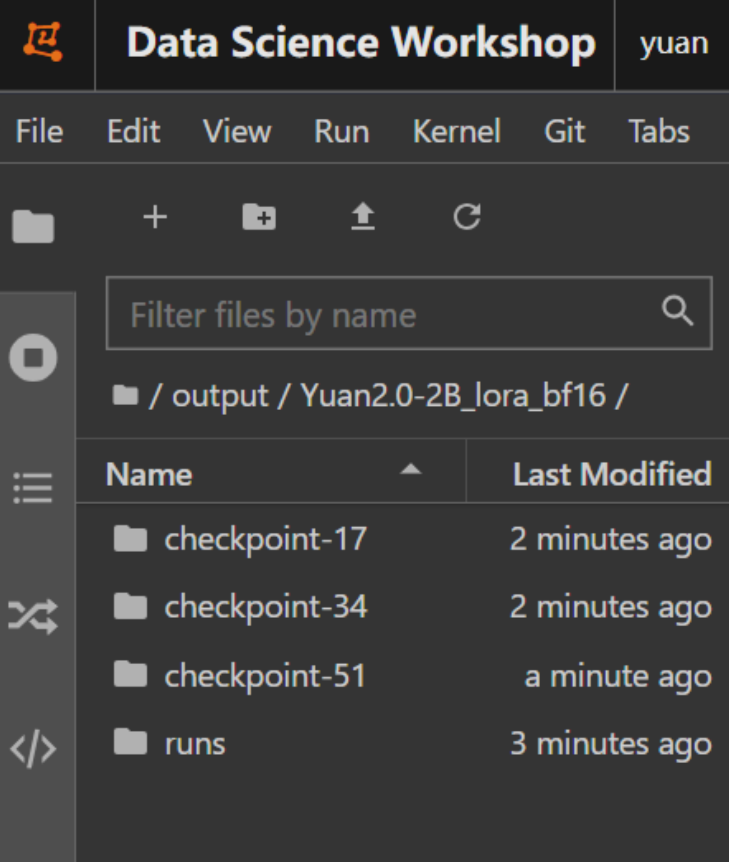
同时,会看到output文件夹中出现了3个文件夹,每个文件夹下保存这每个epoch训练玩的模型
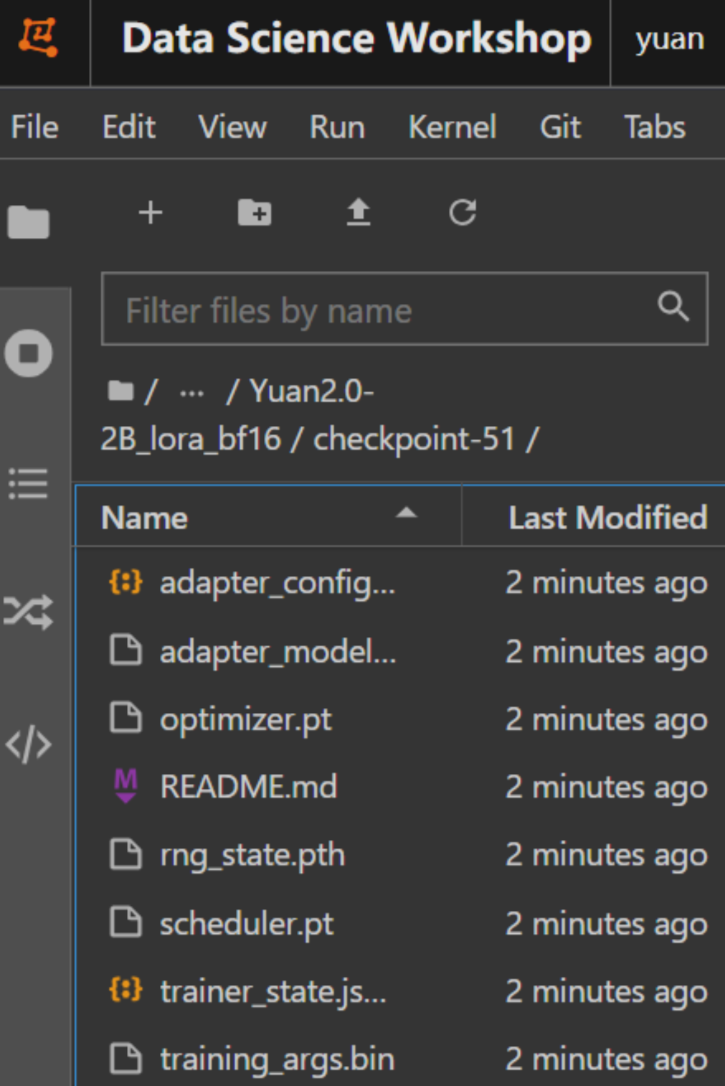
以epoch3为例,可以看到其中保存了训练的config,state,ckpt等信息
2.5效果验证
通过生成函数generate()进行效果验证
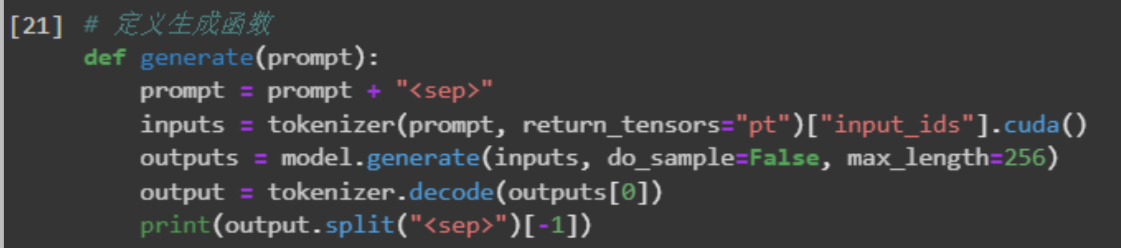
同时定义好输入的prompt template中要和训练保持一致。

最后进行输入样例进行测试
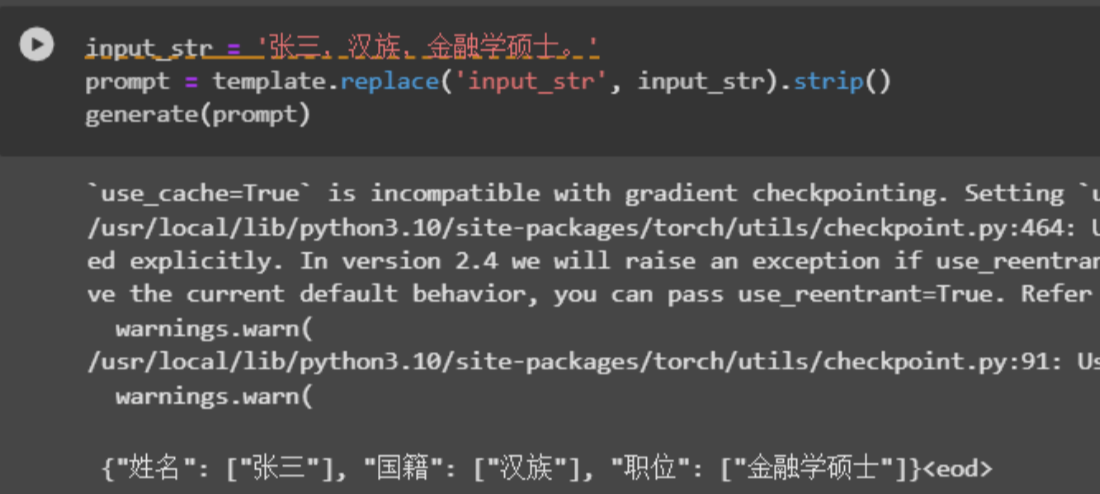
可以看到经过模型微调,模型已经具备了相应的能力。
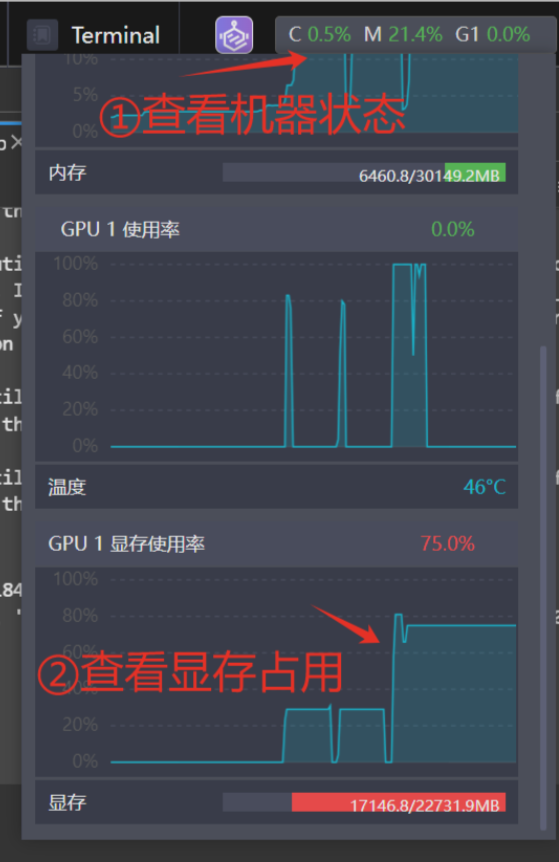
占用17G显存,显存占用的多少和需要训练的模型参数,batch size等相关,可以尝试不同的训练配置。
尝试使用训练的模型
重启内核,可以看到显存已被清空。然后streamlit启动项目即可。
3.1任务挑选和训练集构建
-
原则:任务是否必须微调,单纯通过prompt或者RAG能否解决
-
任务来源:
- 已有的任务:传统的NLP任务,分类,NER等->直接服用开源训练集
- 新任务:构建应用过程中依赖的能力->有无开源训练集可以服用?没有如何收集数据?
-
训练集预处理,收集好的数据需要哪些预处理步骤?数据清洗?去重?
3.2微调实战
- 效果测试:测试集如何来,轻量化微调效果能否达到需求?
- 效果调优:没有达到的原因有那些?数据不够?参数设置不对?需要全量微调?模型太小?
3.3数据集推荐
-
Huggingface dataset: https://hf-mirror.com/datasets
-
openDataLab 数据集: https://opendatalab.org.cn/
-
和鲸社区 数据集: https://www.heywhale.com/home/dataset
git clone https://www.modelscope.cn/datasets/Datawhale/AICamp_yuan_baseline.git